
-
 Kevin Yu
Kevin Yu
- 24 Apr, 2022
Use Packer like a Pro
I’ve been using Proxmox VE for a while now in my Homelab as an open-source alternative for a virtualization platform like ESXi. One useful feature in …

This post is originally published on icloudnative.io blog by 米开朗基杨
If you think GitOps sounds a bit like DevOps, you would be right. GitOps is essentially an operational framework that uses DevOps best practices. In this scenario, we move all cloud operations to Git.
Git is essentially a source code management (SCM) tool developed in 2005 to support software development projects. As Git is already a core part of application development, leveraging Git enforces DevOps best practices and provides access to a robust version control system.
Other benefits include infrastructure automation, continuous integration/continuous delivery (CI/CD), and collaboration.
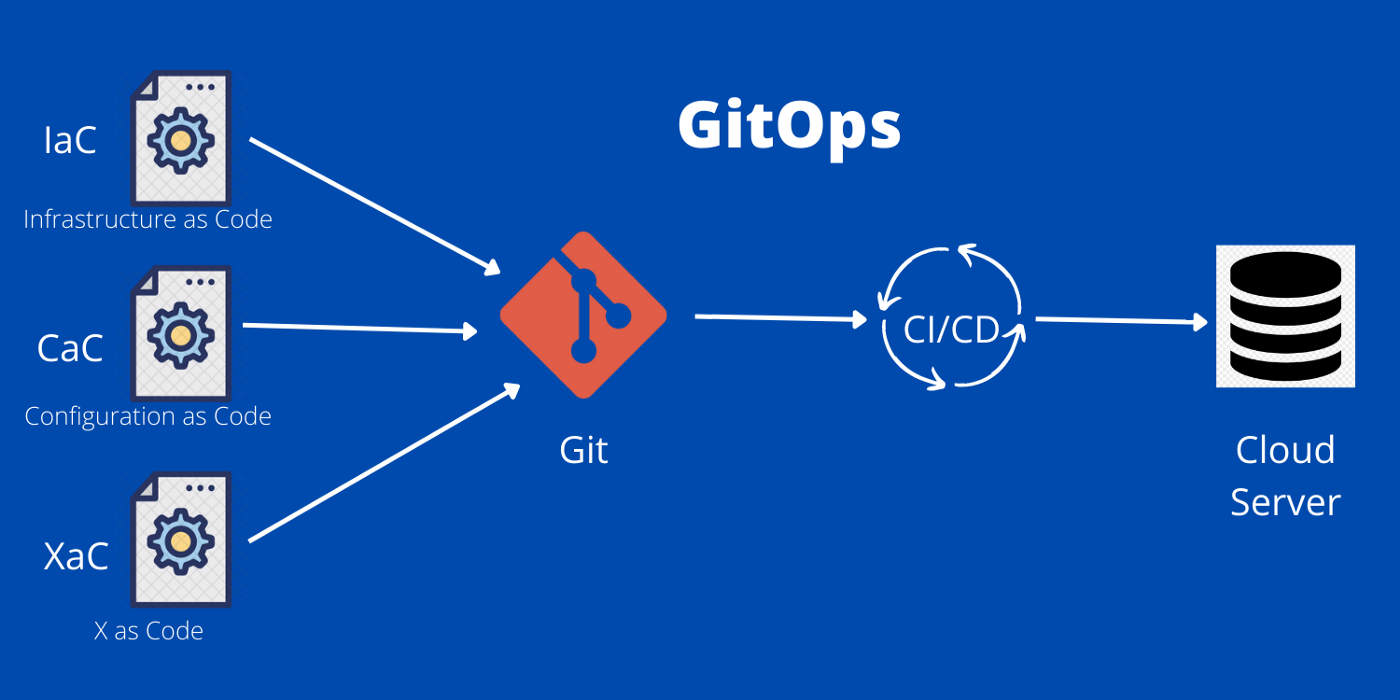
Weaveworks coined the term “GitOps” in 2017 to share the idea that all deployments should be as easy as enacting a code change.
GitOps is a standardized workflow for configuring, deploying, monitoring, managing and updating infrastructure-as-code Kubernetes and all of its components as code. This includes all the applications that run on it.
The core idea here is to have declarative descriptions of the infrastructure and all related elements in their currently desired state in the production environment. In this scenario, an automated process ensures that the described state in the repository and the production environment always match.
In this case, it considers everything related to software deployment:
Codebase changes. Build. Packaging. Application validation. Infrastructure changes. Because of everything that was required, Kubernetes was the ecosystem of choice for GitOps projects. The Kubernetes platform is the perfect solution because of improved developer productivity, higher reliability, increased flexibility, enhanced operational flexibility, improved audibility, compliance, and security.
As GitOps evolved, the definition of “microservices” also changed to accommodate more movement.
As such, we can summarize GitOps as:
An operating model for cloud-native technologies and Kubernetes that comes with a set of best practices to achieve unified Git deployment, management, and monitoring for containerized applications and clusters. A pathway towards efficiently managing applications by applying Git workflows and end-to-end CI/CD pipelines to operations and development. At its most basic, GitOps is about merging intelligent source control with automated CI/CD tooling. For example, whenever you add some code into a Git repository, a lot happens to ensure that your code gets to a relevant target automatically.
For example, if you have code for a new application feature, it automatically ends up in the existing application. Whenever your code declares a network policy update, it’s automatically propagated into the network infrastructure.
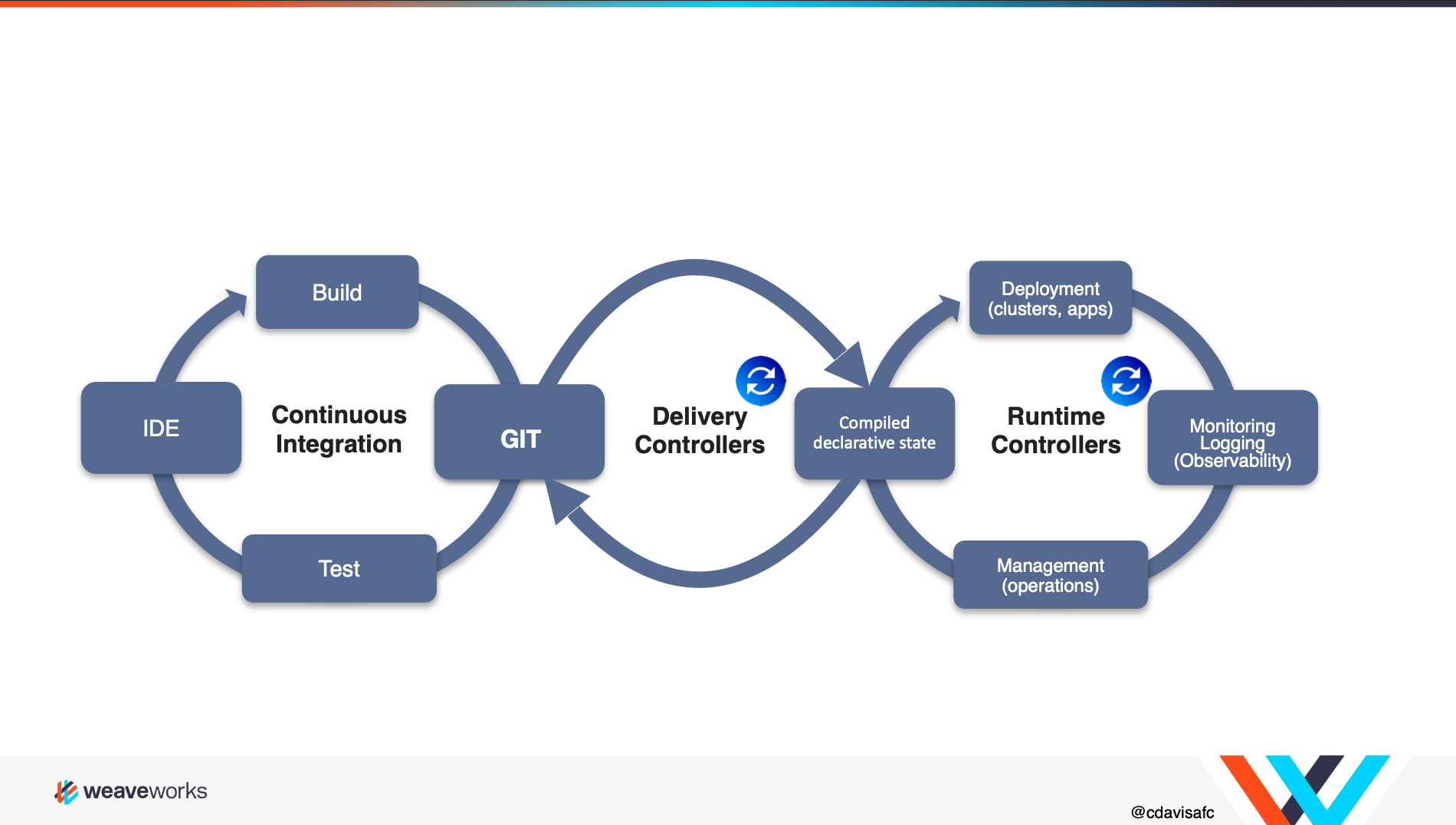
GitOps takes the philosophies and approaches promised to those investing in a DevOps culture and provides a framework to start realizing the results. Organizations who practice DevOps realize significant improvements to the rate of innovation in applications and code, as well as stability, according to the annual State of DevOps Report.
By using the same Git-based workflows that developers are familiar with, GitOps expands upon existing processes from application development to deployment, application life cycle management, and infrastructure configuration. Every change throughout the application life cycle is traced in the Git repository and is auditable. Making changes via Git means developers can finally do what they want: code at their own pace without waiting on resources to be assigned or approved by operations teams.
For ops teams, visibility to change means the ability to trace and reproduce issues quickly, improving overall security. With an up-to-date audit trail, organizations can reduce the risk of unwanted changes and correct them before they go into production.
These changes in code from development to production make organizations more agile in responding to changes in the business and competitive landscape.
In a cloud-native environment with Git as a single source of truth of the system’s current desired state, you can commit all intended operations with a pull request. All changes are observable and auditable, and automatic convergence highlights all differences between the intended and observed states.
GitOps encompasses several guiding principles. These include the following:
As you may not be familiar with IaC, or Infrastructure as Code, this concept is when the end-user defines infrastructure as code instead of manually creating it. This makes our infrastructure much easier to reproduce and replicate but note that infrastructure as code evolved into defining NOT ONLY infrastructure but also Network as Code, Policy as Code, security as Code, Configuration as Code, etc. These are all types of "Definitions as Code", or X as Code. In X as Code, it unifies infrastructure, configuration, network, policy, and so on in code. For instance, instead of manually creating servers, networks, and all the configuration around it on AWS and creating a Kubernetes cluster with certain components. The end-user defines all of these in Terraform scripts, Ansible playbooks code, and Kubernetes manifest files. All these files describe the infrastructure of use, the platform of use, and the configuration of use.
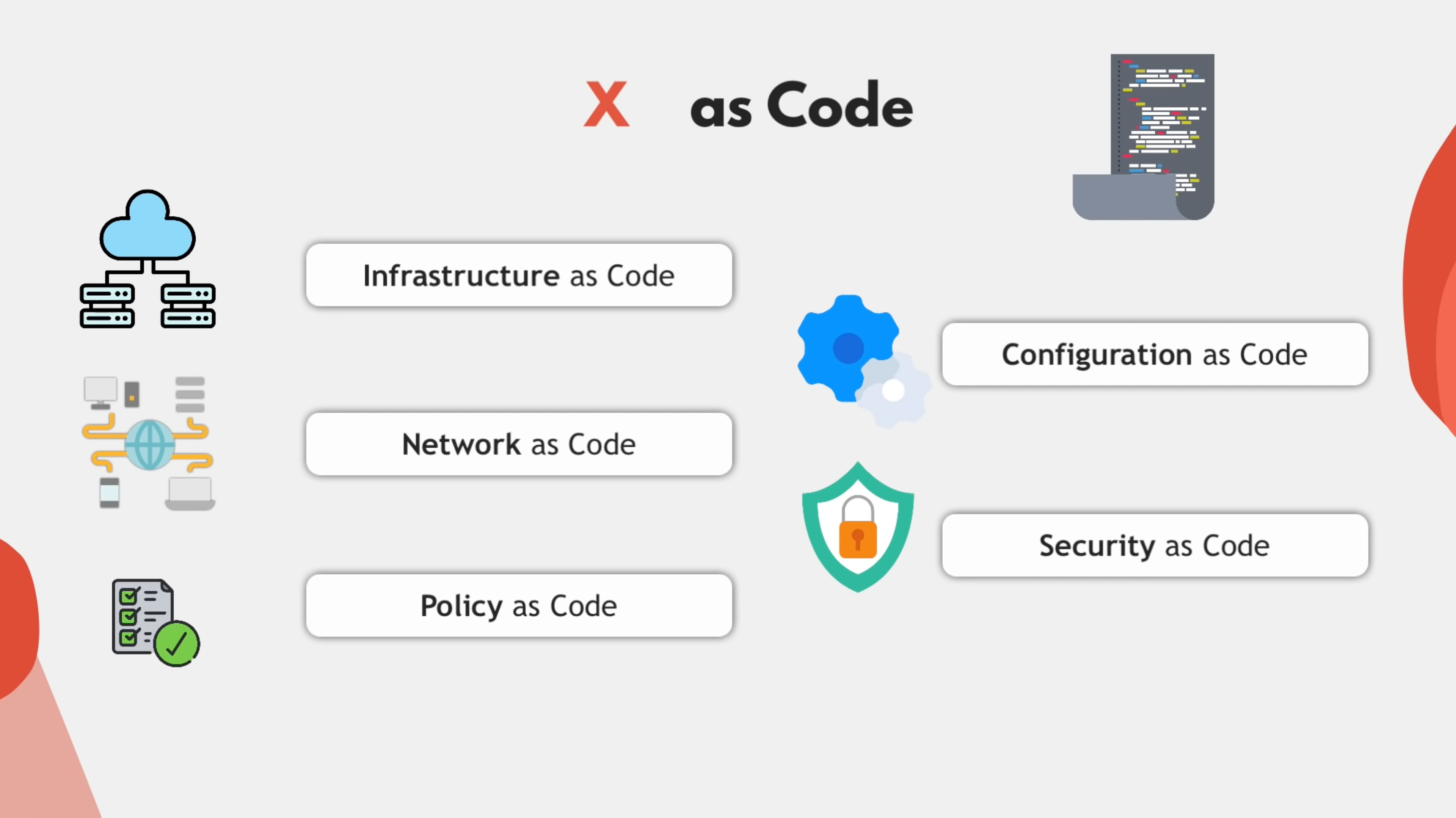
GitOps demands an infrastructure that’s always declarative. It should also concentrate on the target configuration. In other words, it focuses on the desired state and enables the system to execute whatever it needs to realize a desired state.
In contrast, an imperative approach concentrates on a set of explicit commands to change the desired state. This makes reconciling a challenge as imperative infrastructure is unaware of the state. You must store the declarative state of the entire system in Git. In this case, Kubernetes is the most prolific declarative infrastructure that allows you to keep its state in Git.
When it comes to GitOps, the canonical state is essentially the “Single Source of Truth” state. For example, when the state is stored and versioned in source control, it must be viewed as a source of truth.
In this case, you can test objects on how equal they are when compared to the canonical form. Whenever there’s a deviation in the state, it can quickly recognize and reconcile it back to the canonical state in source control.
Once you store the declared state in Git, you must allow all changes to that state to be applied automatically to your system through pull requests (PR) or merge requests (MR). You won’t need cluster credentials to make changes to the system.
There’s also a segregated environment in GitOps where the state definition lives outside. As a result, you can separate what you do and how you do it. What’s excellent about GitOps here is that it favors a low barrier of entry. In this case, you won’t achieve immediate deployment or reconciliation until you achieve a new canonical state.
Once you declare the state of your system and keep it under version control, you can use software agents to alert you whenever reality and your expectations don’t match.
Software agents also help ensure that the whole system is self-healing to mitigate the risk of human error and more. In this scenario, software agents act like an operational control and feedback loop.
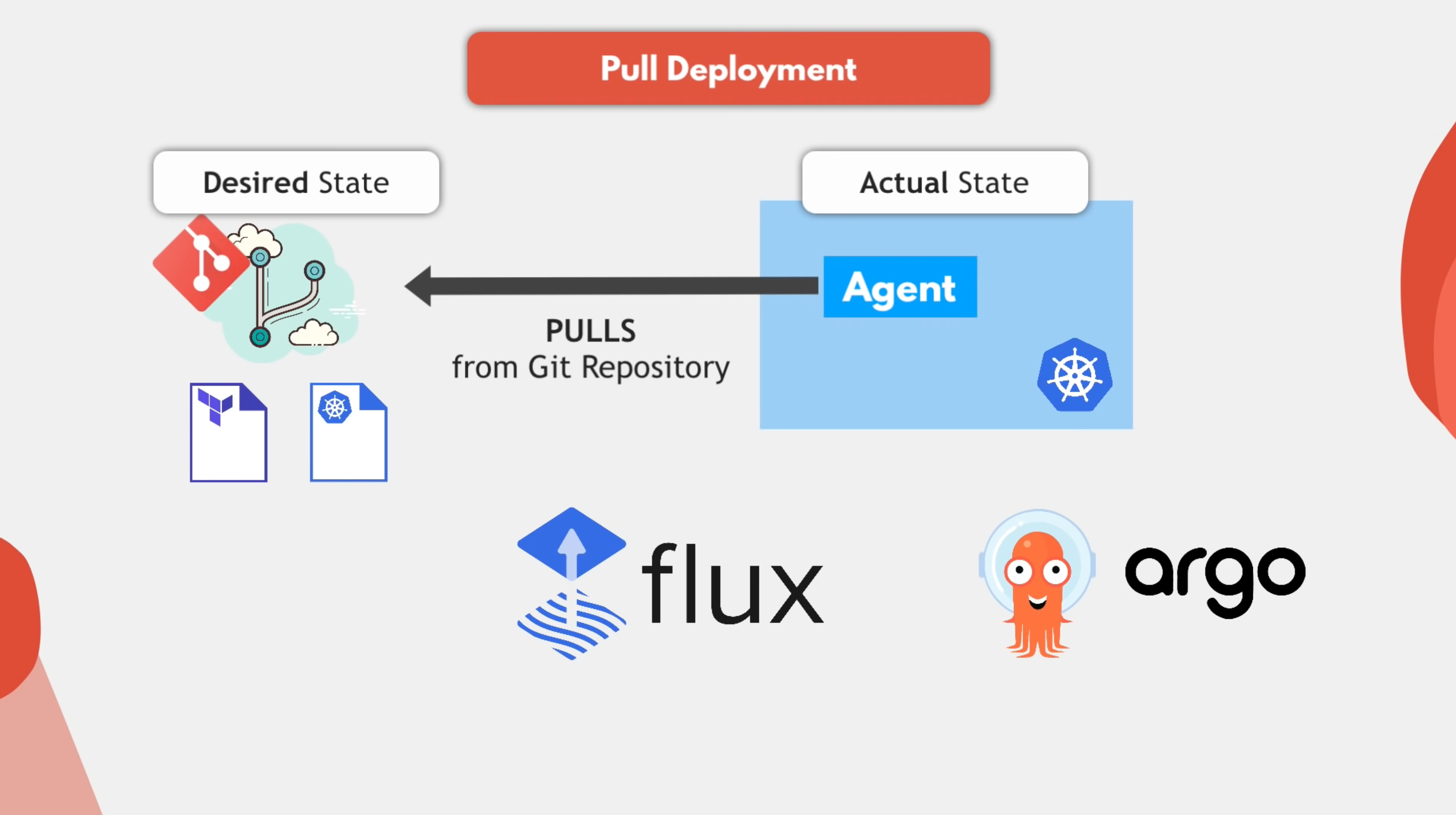
Reconciliation is the earliest concept in Kubernetes, which means the process of ensuring that the actual state of the system is consistent with the expected state. The specific way is to install an agent in the target environment. Once the actual state does not match the expected state, the agent will automatically repair it. The repair here is more advanced than Kubernetes’ fault self-healing. Even if the arrangement list of the cluster is manually modified, the cluster will be restored to the state described by the list in the Git warehouse.
Given these design philosophies, let’s take a look at the workflow of GitOps:
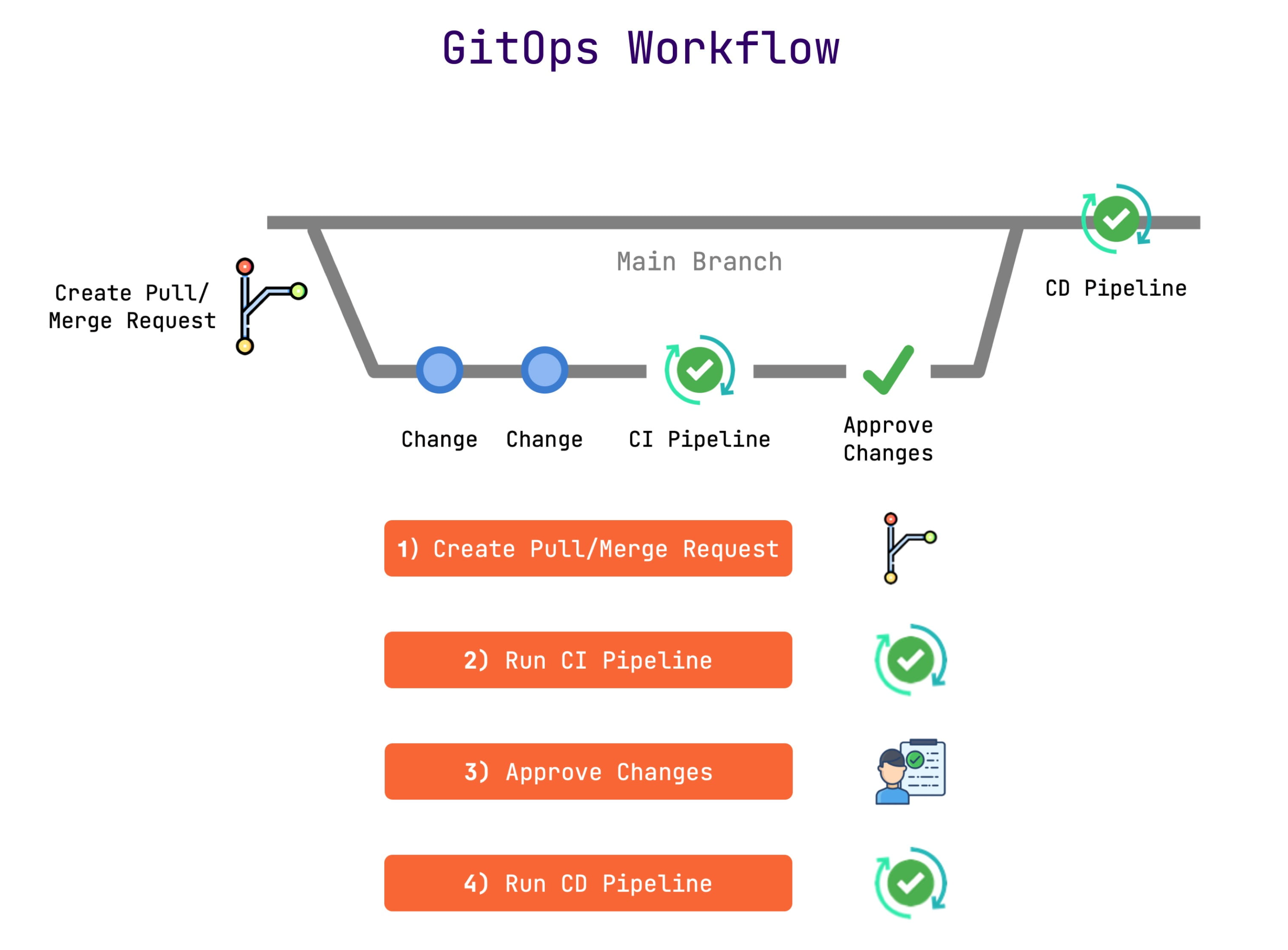
A GitOps-based workflow means all changes to application environments will be initiated by a pull request to a Git repository holding the Kubernetes manifest files.
Practically speaking, there is no CI/CD as a single concept. However, there are CI and CD!
Traditional CI/CD defines both the CI and CD process within a single pipeline.
Most CI/CD tools available today use a push-based model. A push-based pipeline means that code starts with the CI system and may continue its path through a series of encoded scripts or uses ‘kubectl’ by hand to push any changes to the Kubernetes cluster.
The reason you don’t want to use your CI system as the deployment impetus or do it manually on the command line is because of the potential to expose credentials outside of your cluster. While it is possible to secure both your CI/CD scripts and the command line, you are working outside the trust domain of your cluster. This is generally not good practice and is why CI systems can be known as attack vectors for production.
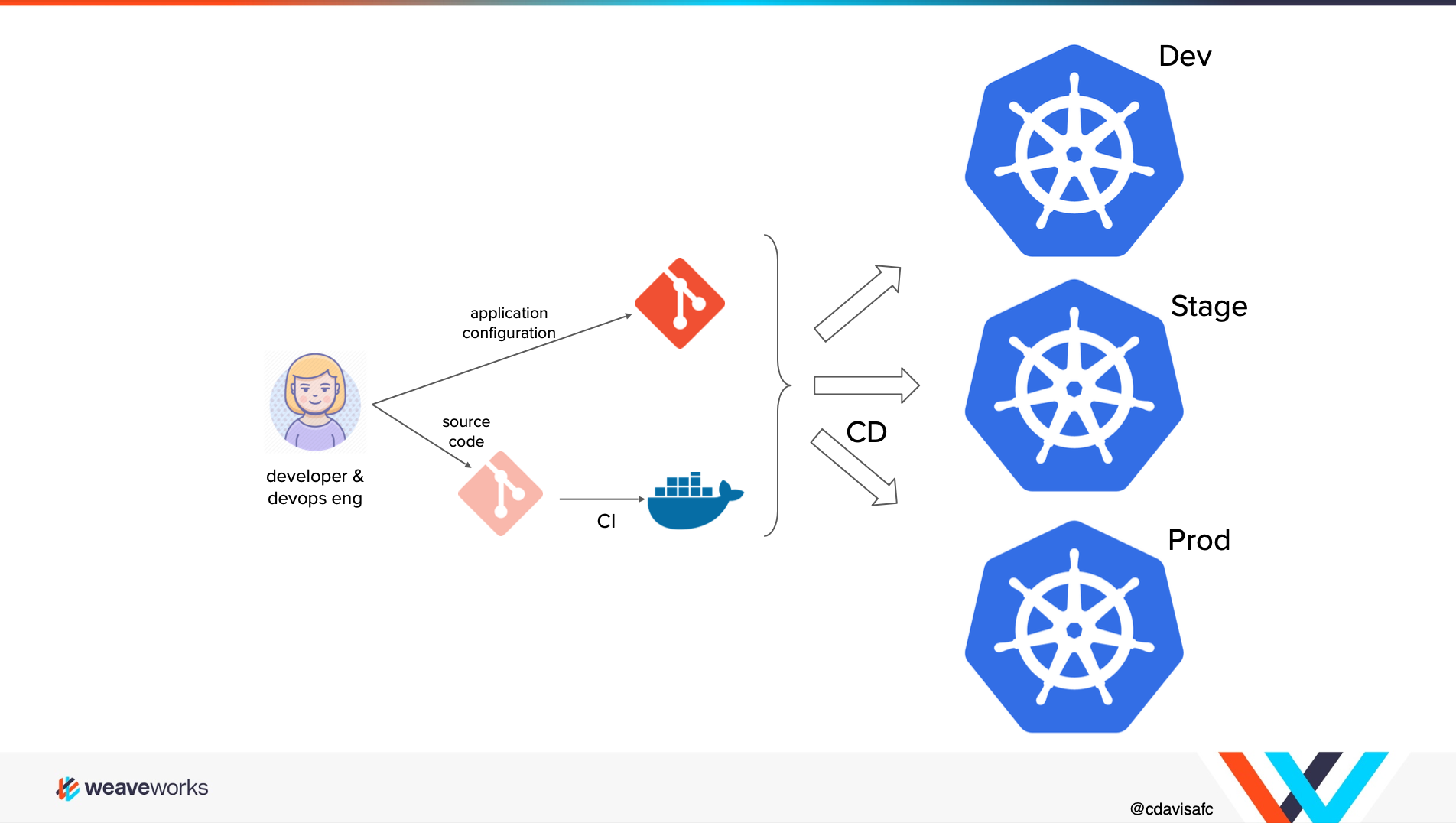
GitOps-based CICD uses a pull strategy that consists of two key components: a “Deployment Automator” that watches a git repository or an image registry, and a “Deployment Synchronizer” that sits in the cluster to maintain its state.
Developers push their updated code to the code base repository; where the change is picked up by the CI tool and ultimately builds a Docker image. The ‘Deployment Automator’ notices the image, pulls the new image from the repository and then updates its YAML in the config repo. The Deployment Synchronizer, a component that comes with the GitOps tooling of choice(ArgoCD or FluxCD) in the Kubernetes cluster, then detects that the cluster is out of date, and it pulls the changed manifests from the config repo and deploys the new image to the cluster.
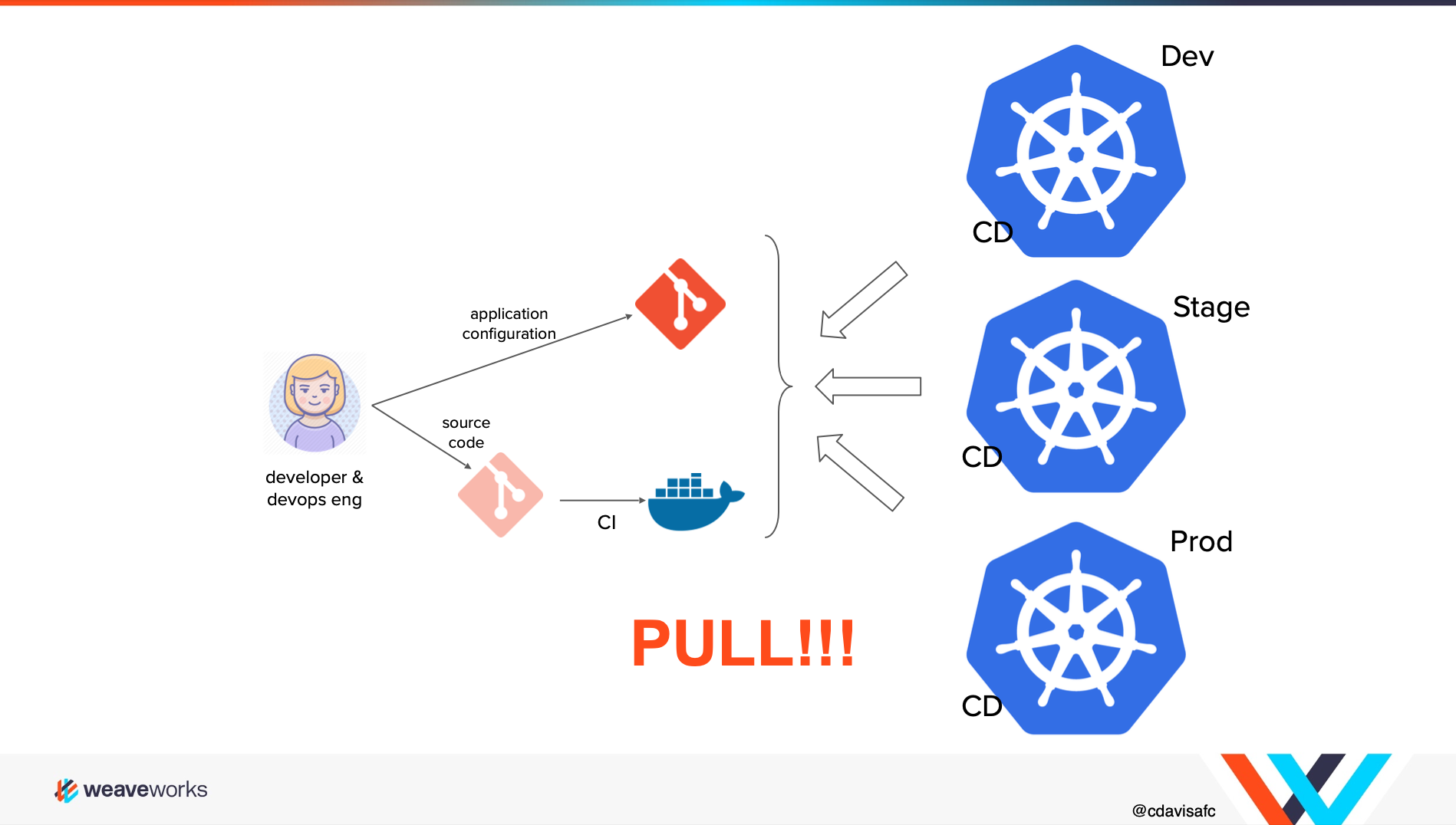
GitOps is a supplement to the existing DevOps culture. It uses a version control system like Git to automatically deploy the infrastructure. The deployment process is visible, and any changes made to the system can be viewed and tracked, which improves productivity, security, and compliance. Moreover, GitOps provides more elegant observability, which can observe the deployment state in real-time and take actions to keep the actual state consistent with the expected state.
Moreover, in GitOps, the whole system is described in a declarative way, which is naturally suitable for the cloud-native environment, because Kubernetes is also designed in such a way.
Written By
In the upcoming months and years, I want to help make learning Machine Learning and Cloud Computing topics easier by writing lots of articles showing of practice cases on Cloud and Edge devices. Furthermore, I’m planning on creating an AI and Cloud …
I’ve been using Proxmox VE for a while now in my Homelab as an open-source alternative for a virtualization platform like ESXi. One useful feature in …

Building images from a standard Dockerfile typically relies upon interactive access to a Docker daemon, which requires root access on your machine to …