Edge Computing places workloads closer to where data is created and where actions need to be taken and address the unprecedented scale and complexity of data created by connected devices. As more and more data come from remote IoT edge devices and servers, it’s important to act on the data that makes the biggest impact. Acting quickly on the right data can help companies seize new business opportunities, increase operational efficiency, and improve customer experiences.
In this post, we will discuss the insights, basic concepts, and key use cases of edge computing.
Refrence:
Essense of Cloud Native
Cloud-Native applications changed enterprise software, forever replacing traditional methods of software — releasing, deploying via ongoing operations because traditional enterprise software was optimized for a world without the internet. By the same token, embedded computing at the edge has quickly become the wrong tool for the job, soon to be replaced by the internet-centric edge known as Cloud-Native Edge Computing.
So, what is Cloud-Native Edge Computing? It is a purpose-built computing environment that enables machines to work in real-time not as defined by humans, who can tolerate a second or two of latency, but by machines, for whom instant means nanoseconds or less. It is an environment that is orchestrated from the cloud, but not dependent on it, and without the need for remote IT experts distributed globally and available 24/7 to maintain.
For instance, a self-driving car can only swerve out of the way of a pedestrian if it has edge computing without latency. It can quickly learn and have its “driver” updated in an instant with the latest data from all the other cars in a cloud-native edge. There’s no time to think when there’s an emergency, and if there is a dependency on the cloud, a device can’t ‘think’ fast enough because of latency.
What is Edge Computing?
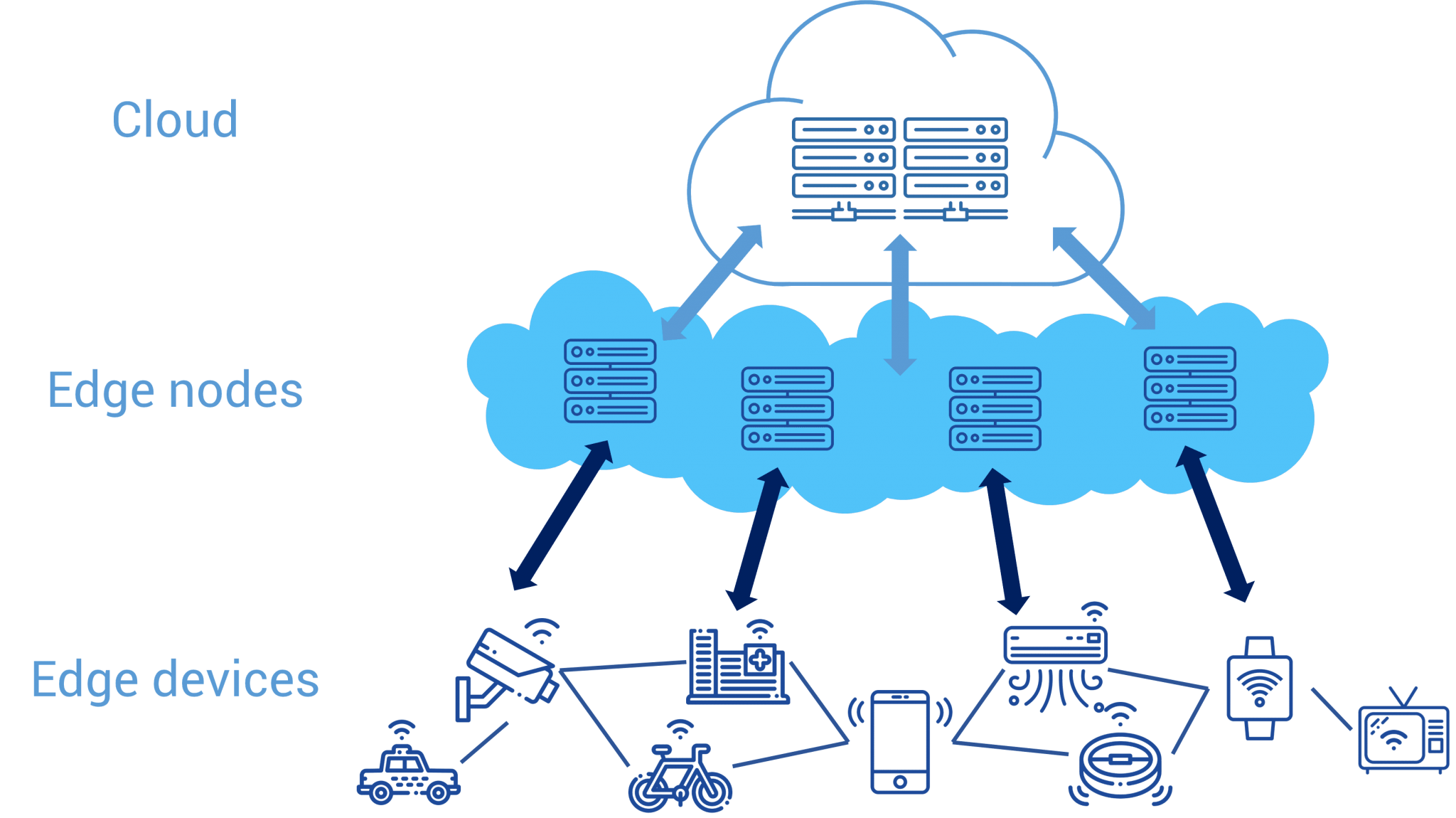
We define Edge Computing as being about placing workloads as close to the edge, to where the data are being created, and where actions are taken, as possible.
Why Now?
As the pace of business accelerates, the desire to gather more information about any business environment and improve it in real-time comes alongside expectations for faster response times: think retail robots, predictive maintenance in factories, and self-driving city buses. Speed forces a shift to a more distributed infrastructure, massively scalable IoT, and possibly even new business models, such as the equipment-as-a-service (EaaS) sector we’re already starting to see.
Ultimately, applications on the cloud-native edge will not only improve operations, enhance the consumer experience, but will keep us all safe and secure as physical systems become connected to the internet. It is the only way for machines to operate in real-time securely, and thus scale IoT operations. And that is true digital disruption.
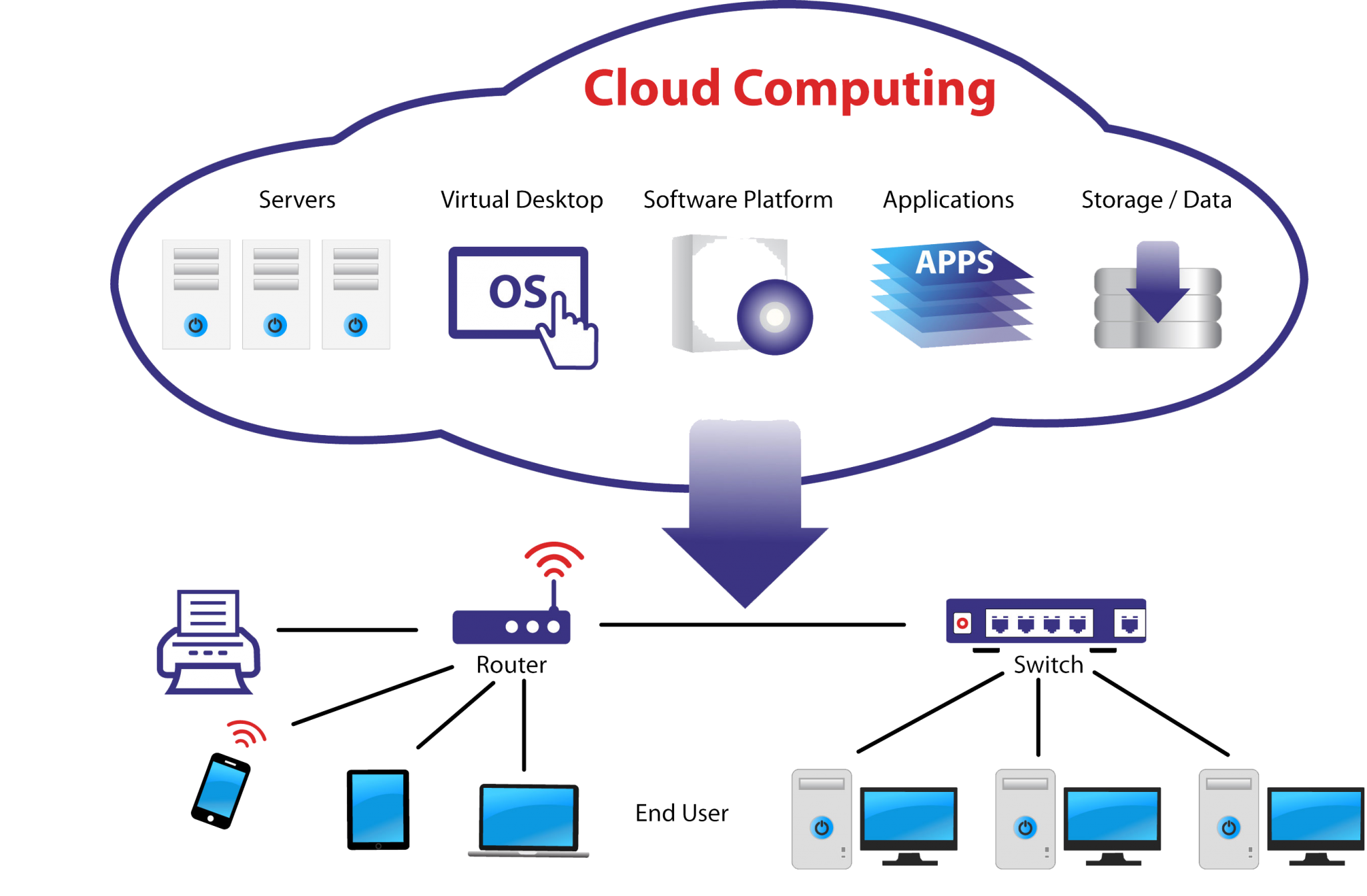
Utilization of Cloud
Data
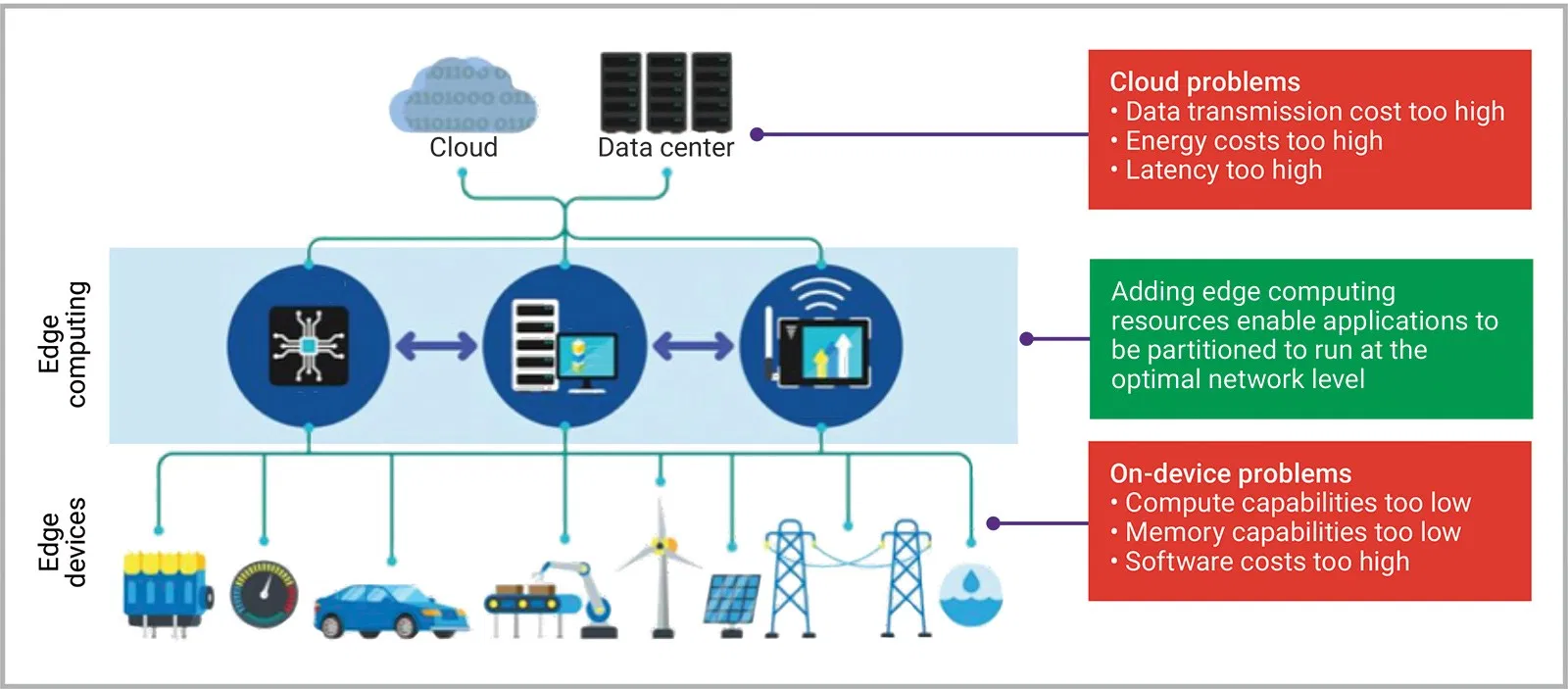
Where do data come from? We often think about data existing in the cloud, where we might do analytics and AI activities that process that data, but that’s really not where the data originally was created. The data is created, really, by us as human beings, in our world, in the environments that we operate, in the places where we do work. It comes from us in our interactions with the equipment that we use as we’re performing various tasks. It comes from the equipment itself, and it’s produced as a byproduct of our use of that equipment.
If we want to make use of the edge, and we want to place workload there, we have to start by thinking about what data ends up coming back to the cloud.
Hybrid Cloud
when we talk about clouds, let’s talk about both private and public clouds. Frankly speaking, where we put that data, and where we end up processing that data for things like aggregate analytics, trend analysis, is still likely to occur in the cloud, in the hybrid cloud .
Network
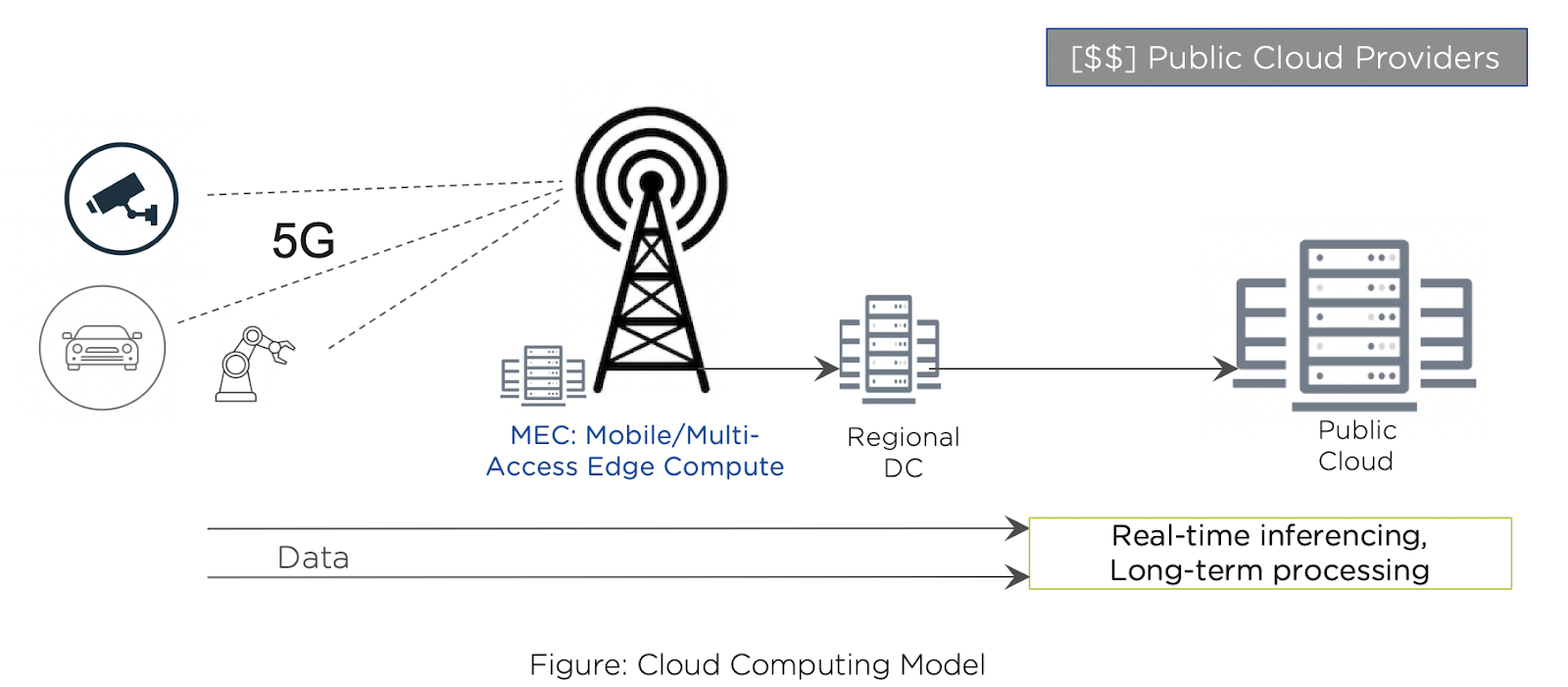
Now, it turns out the network providers are also looking at the world of networking, the facilities that they provide, and how they can bring workloads into the network itself. So, we can label the network edge. That’s sort of how they refer to it themselves. Oftentimes, you’ll hear the term edge being used by the network providers as being about their own network. 5G opens up the opportunity for us to communicate into the premises where work is performed, onto the factory floor, into the distribution centers, into the warehouses, into the retail stores, into banks, hotels, you name it. There is an opportunity for us to introduce compute capacity into those environments and communicate with that through 5G networks.
Edge Computing
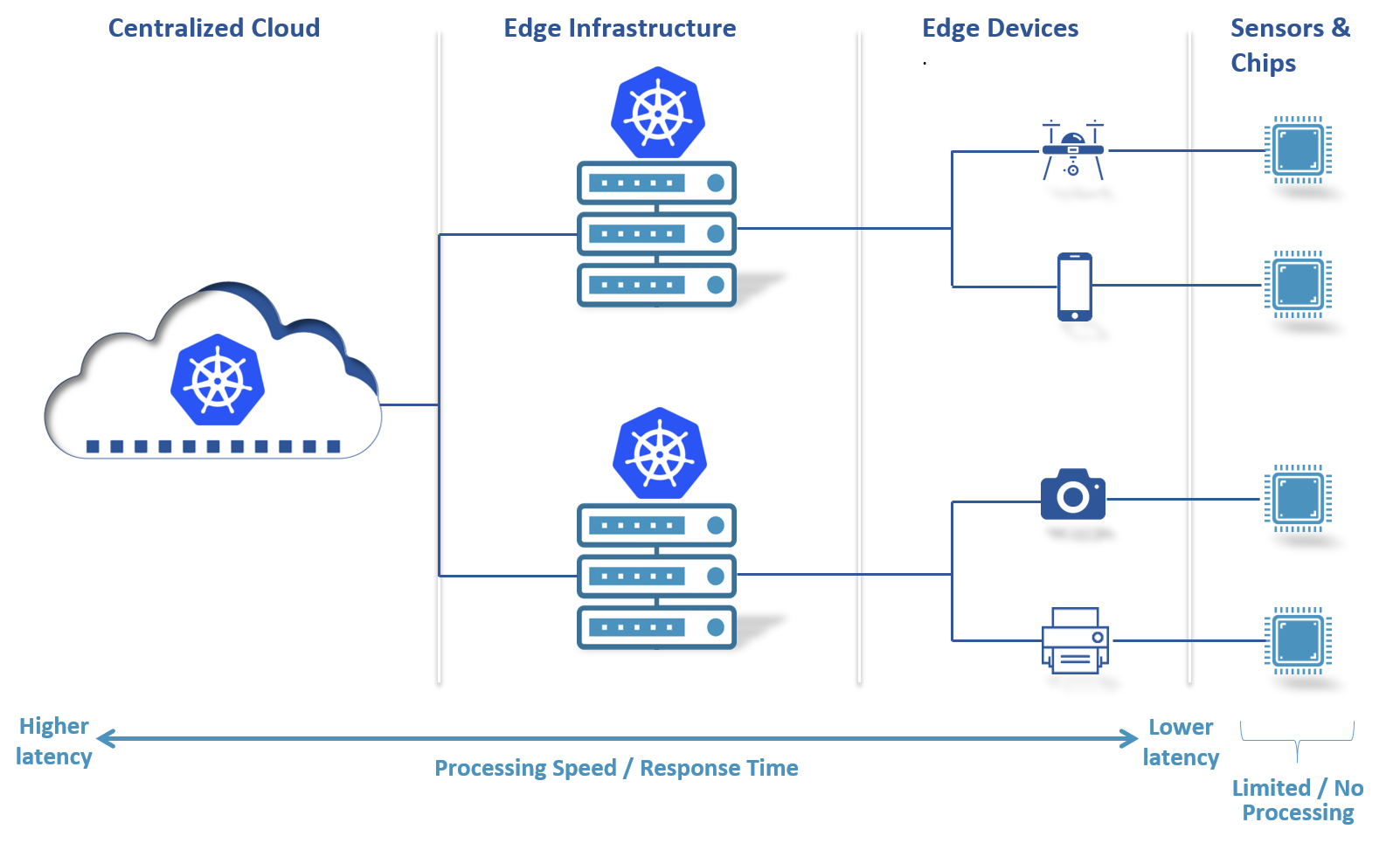
Computing Capabilities
There are two kinds of Edge Computing Capabilities that we often find in the environment One is what we call an Edge Server. Another place where we can perform work in the edge, in the on-premise locations, are in what we think of as Edge Devices.
An Edge Server is, you can think of as basically, a piece of IT equipment. It could be a half rack of maybe four or eight blades, it could be an industrial PC, but it’s a piece of equipment that was built for the purpose of computing IT workloads.
An Edge Device is interesting because what it is, first and foremost, is a piece of equipment that was built for some purpose. It could be an assembly machine, it could be a turbine engine, it could be a robot, it could be a car. They were built first and foremost to perform those functions. They just so happened to have compute capacity on it, and in fact, what we’ve seen over the last few years is that many of the pieces of equipment that we had before, that we refer to as IoT devices, now have grown up, and we’ve seen the addition of more and more compute capacity on these devices.
Let’s take a car as an example to demonstrate the computing capabilities as an Edge Device. The average car today has 50 CPUs on it. Almost all new industrial equipment have compute capacity built into that equipment. They have the ability for us to deploy containerized workloads onto these devices, indicating that now that becomes a place where we can do work that we couldn’t do before. Let’s say, for example, you’ve got a video camera built into an assembly machine, an assembly machine that’s making parts. Maybe it’s making metal boxes of some sort, you can put a camera on that. You can put an analytic on that camera that now looks at the quality that that machine is producing.
Now it’s very common that a lot of these operating environments also have edge servers. Again, just keep it in mind these things are pieces of IT equipment, so it might be a half-rack sitting on a factory floor that is today being used to model the production processes or to monitor for production optimization, and whether the production is being performed as efficiently, and as with as much yield as we want. Therefore, these are places where work can be performed.
Discussion
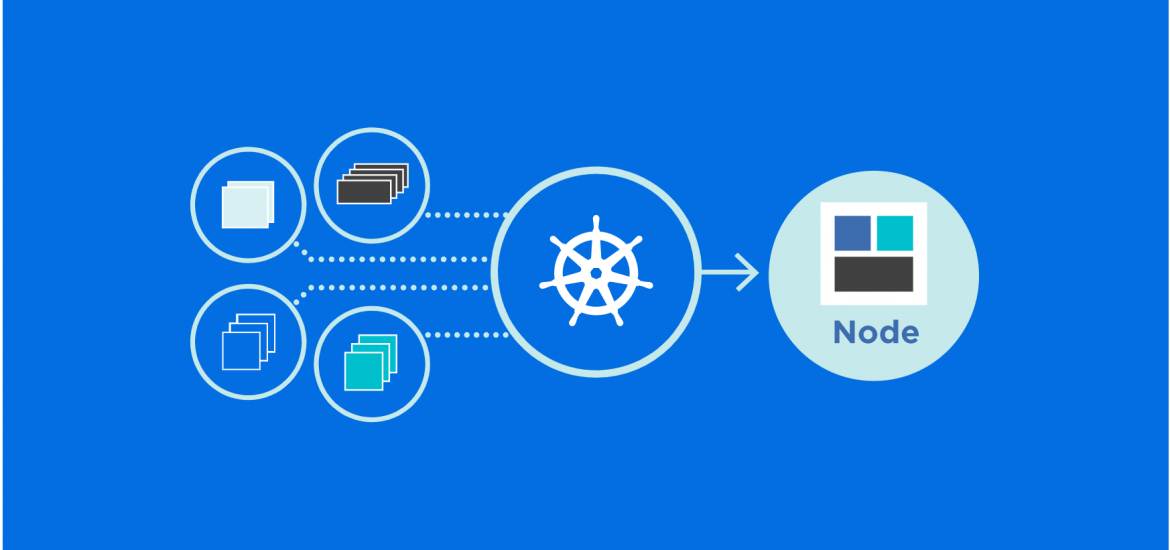
Edge Servers, in comparison to Edge Devices, are pieces of IT equipment, oftentimes are much bigger. Kubernetes provides us an orchestration tool to manage multiple devices in a server. Normally, we host the Kubernetes on the Edge Server because it provides us the capacity, enough Computing Power to handle complex tasks. With Kubernetes, we can easily get the elastic scale, the high availability, and the continuous availability out of the workloads that are deployed on these edge servers.
what happens in these environments? How do we manage these environments? How do we make sure the right workloads are placed in the right place at the right time? First of all, we think about what we’ve done in the cloud. We know that in the cloud it’s important to build workloads as containers. This is something that we have developed for scaling, efficiency, consistency, and that almost all of the public cloud providers, and certainly most of the private cloud suppliers, now enable with Kubernetes running in the cloud. We can take that same concept, and we can use it to package the workloads and manage distribution out into these edge computing scenarios.
Secondly, because these things are often built for use in hybrid cloud scenarios where we have built hybrid cloud management, we can begin to reuse those concepts as a technique for handling the distribution of those containers into these edge locations. However, there are several problems.
One of them is just thinking about the volumes, the numbers of devices out there. We estimate there are about 15 billion edge devices in the marketplace today, and that that grows to about 55 billion by 2022, and there are some estimates that that will grow to about 150 billion by 2025. If that’s true, that means that every enterprise out there will have literally tens of thousands, hundreds of thousands, maybe even millions of devices that they have to manage from their central operations. We have to have management techniques that are able to distribute workloads into these places on a massive scale without requiring individual administrators going out and assigning those workloads to individual devices.
We also have an issue of diversity. These devices come in many different forms. They have different purposes, they have different utility, they make different assumptions about their footprint, but also what operating system they use, what kinds of work they’re going to perform on these devices.
Finally, security is an issue. In these environments, these devices out here on the edge exist outside the boundaries of the IT data center. They don’t have the protections that we typically associate with the hybrid cloud environments, physical protection, the uniformity, the consistencies that we look for, typically, when we certify security in these kinds of environments. We have to now think about how do we ensure that workloads do not get tampered with when they’re deployed out to these systems? How do we make sure that the machine itself, if it does get tampered with is something that we can detect, and respond to, and remediate? We have to make sure that the data that we associate with these workloads are properly protected, not only from the fact that this data may be moved back into the network, through the network and into the cloud, but also because the movement itself represents a point of vulnerability. If we can move the workloads to the edge, and avoid having to move sensitive data back to other locations, then we’ve actually reduced the potential for people to find attacks on that data.
To sum up, all of these things together are the things that will, on the one hand, inhibit the use of edge computing, but on the other hand become an opportunity, an opportunity for vendors to introduce management controls that are able to handle that diversity, and the dynamism, the ability to protect data in the right places or at the right time, and finally, to build an ecosystem, which of course is just as important as everything else.
Thoughts
To wrap up this post, it is important that we acknowledge that the edge computing world is growing. This is going to grow rapidly. It will have as much impact in the world of enterprise computing as mobile phones did in the world of consumer computing. If you think about the changes that have occurred as a consequence of the mobile phones, you are going to see as much change occur in enterprise computing as a consequence of edge computing that we saw over the last 10 years with mobile computing. So, this is a world that’s growing. This is a world that has lots of interesting complexity to it, but where, if we can solve these issues, will yield an enormous amount of value to our customers.


 Kevin Yu
Kevin Yu